Transformer Parallelism: Tensor and Sequence Parallelism
There have been many different popular Transformer sharding strategies over the years, and some of the well-known ones (popularized by Megatron-LM) are Tensor and Sequence Parallelism.
Tensor Parallelism was described in https://arxiv.org/pdf/1909.08053 by researchers from NVIDIA, and it basically shards the attention QKV weights, attention projection weights, and MLP up & down projection weights along the hidden / embedding dimension.
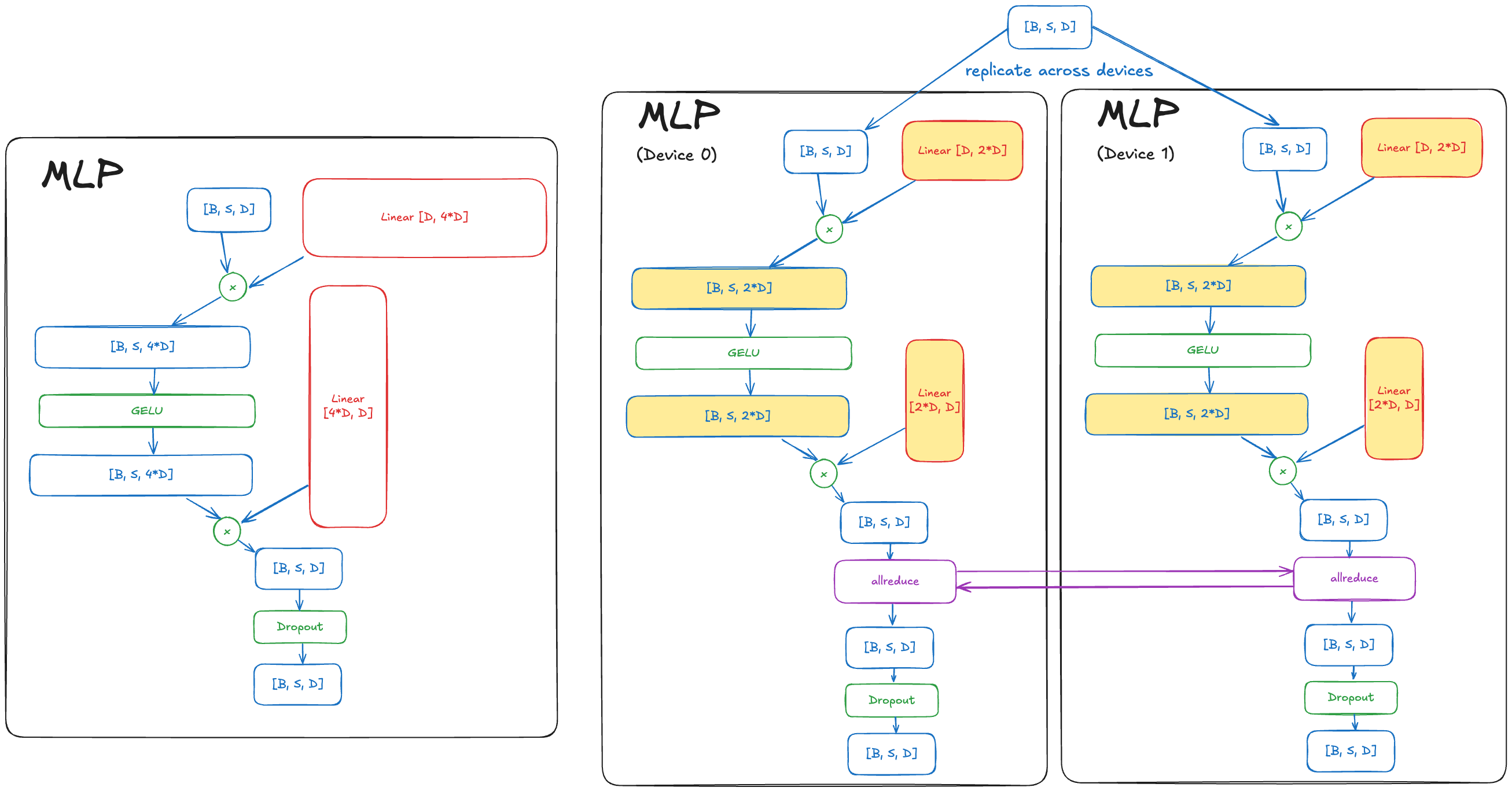
In addition, some of the activations are also sharded too – see the picture below. If the weights of a Linear layer are sharded in a Columnwise Parallel fashion (i.e. the Column dimension is the one being sharded), then the activations (or outputs) of that layer will be sharded. If the weights of a Linear layer are sharded in a Rowwise Parallel fashion (i.e. the Row dimension is the one being sharded), then the inputs to that layer must also be sharded for the matrix multiplication to work. Tensor Parallelism in Megatron-LM basically uses a pattern like this:
- An unsharded input Tensor applied to Columnwise Parallel Linear layer produces an output that is sharded.
- Then, that sharded output goes through pointwise operations on the sharded tensor.
- Then, that sharded tensor is applied with a Rowwise Parallel Linear layer that produces an unsharded output on every replica.
- The unsharded outputs are combined together via an allreduce (with the sum as the reduction operation).
Below is a diagram of this to help visualize all the dimensions, with the non-sharded version on the left and the sharded version on the right. Do note that with FlashAttention, a majority of the activations in the Attention block are not materialized to GPU HBM in practice anymore. Here are the Excalidraw links: mlp, attention. The tensors highlighted in Yellow are sharded in a Tensor Parallel fashion (along the hidden / embedding dimension).

One thing you might notice is that we can shard some of the activations of the model along the sequence dimension too (denoted by S in the pictures). Again this was proposed by NVIDIA (in https://arxiv.org/pdf/2205.05198) and popularized by Megatron-LM. This only has a few small changes – instead of doing 2 allreduces, we do 2 reduce-scatters and 2 all-gathers. This is actually the same amount of communication as before! NCCL does a Ring allreduce within a node, and a Ring allreduce is composed of a reduce-scatter and an all-gather. With recent hardware NCCL might use SHARP instead of a Ring, but the same principle applies.
The diagram is attached below, and here’s the Excalidraw link. The tensors highlighted in Yellow are sharded in a Tensor Parallel fashion as before, while the tensors in Red are sharded in a Sequence Parallel fashion. The pattern to note is instead of doing an allreduce to combine unsharded tensors, we do a reduce-scatter to both do the required reduction, but also shard the tensor along the sequence dimension instead of the hidden / embedding dimension. And later on we do an all-gather so that all ranks have all replicas before the Attention or the MLP portions, which still operate in the same Tensor Parallel fashion as before.
The only reason we can do this is because the operations such as LayerNorm or Dropout do not require a reduction across the sequence dimension! If they did require that then we would need to do an additional communication collective in that operation, which reduces the point of sharding it again in the first place.
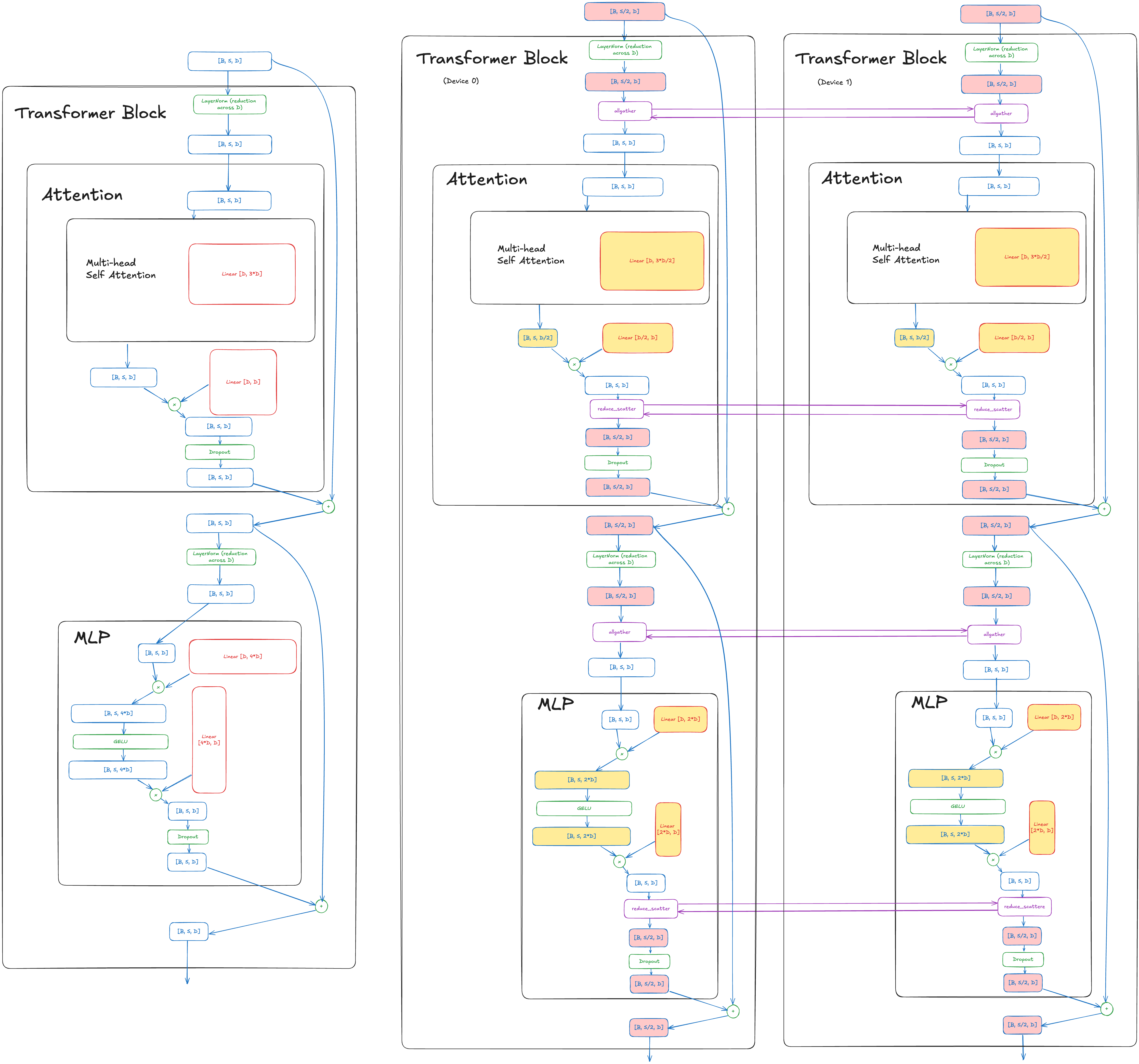
One additional detail that readers might notice is for the entire Self Attention portion of the computation, nothing is sharded along the sequence dimension. This is much trickier than what we did above, since at a first glance the Self Attention portion of the model requires the entire sequence dimension to perform the computation (since it does a softmax which does a reduction across the sequence dimension), whereas the LayerNorm and Dropout portions do not (the LayerNorm reduction is across the hidden dimension, not the sequence dimension).
However there is a way to do this! NVIDIA calls this additional feature Context Parallelism in Megatron-LM, which is basically just an implementation of the Ring Attention paper. This will be discussed in a later post!